主题
报表开发
概述
报表设计器是一款基于浏览器的高效数据可视化工具,采用类Excel的交互模式,为用户提供低学习成本的报表设计体验。
通过创新的在线设计引擎,用户可快速构建复杂的企业级数据报表,实现数据采集、分析与展示的一体化解决方案。
典型应用场景 ✓ 财务月度报表自动化 ✓ 销售数据动态看板 ✓ 生产制造KPI监控 ✓ 人力资源统计分析
报表管理
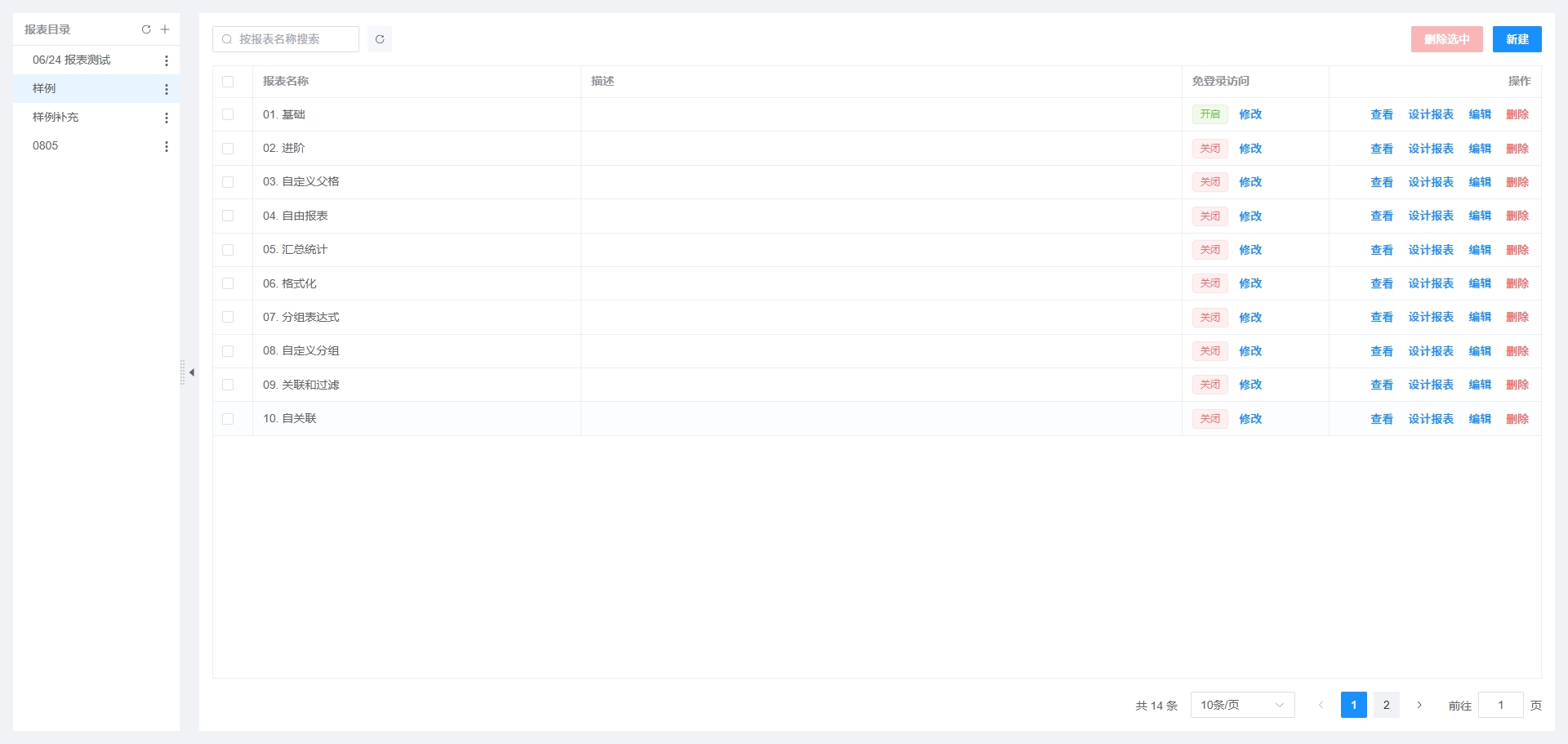
在左侧导航菜单中选择【可视化】【报表开发】进入报表管理界面。
左侧为报表目录,每个目录下可创建多张报表,如下图所示:
数据集
报表开发和要涉及两部分工作:
- 配置一组结构化的数据,称为数据集
- 在报表设计器中设计报表模板
准备好数据集后,将数据集中的数据具体展开,填入新报表中的适当位置,即可得到一份详细的报表呈现。
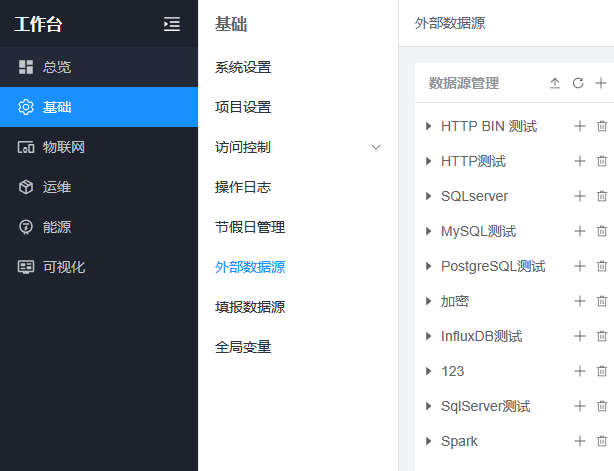
外部数据集
在平台外部数据源中配置的数据集。
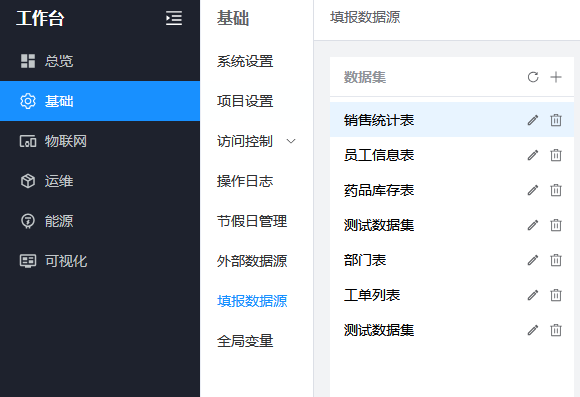
填报数据集
在平台填报数据源中配置的数据集。
设备数据集
在平台物联网模块配置的设备和点位值,可以作为设备数据集在报表中使用。
报表设计器
静态文本
任意选中设计器中的一个单元格,在右侧面板中,可以看到它的类型是「文本」,这是所有单元格的默认类型。
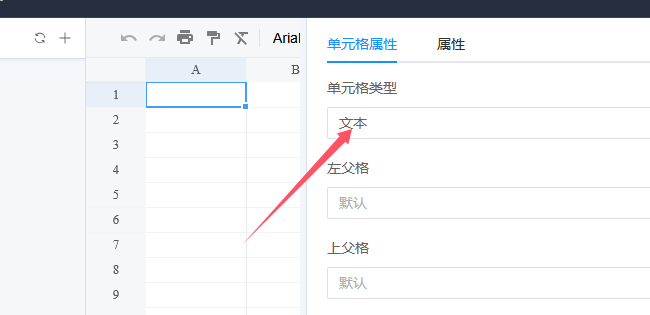
单元格类型还有其他两种:
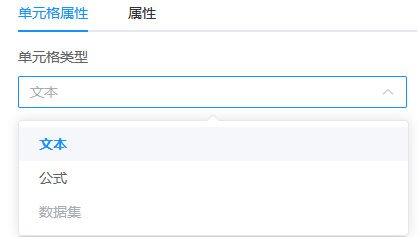
术语「单元格类型」:模板中的单元格有「文本」、「数据集」、「公式」三种类型。
有时,我们也称单元格类型中的「文本」为「静态文本」,称「数据集」为「字段」或「数据集字段」。
我们这里先介绍「文本」类型的单元格,另两种类型在后面的章节介绍。
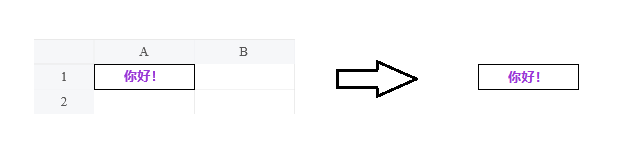
我们在设计器中输入一些文字,调整一下样式,依次点击页面右上角的保存和预览按钮。
可以看到,展开之后,模板中静态文本的单元格展开后原样出现在了对应位置。
添加数据集
点击左侧数据集面板右上角的加号,将配置好的数据集添加到报表中。
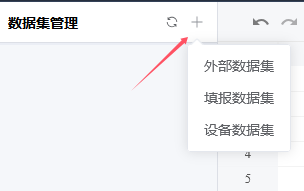
外部数据集:字段来自于外部数据集的「字段」,查询参数对应外部数据集中的「变量」
如果外部数据集没有配置字段,则加入报表后无法使用。
填报数据集:字段来自于填报数据集的「字段设置」,查询参数对应字段设置中「可搜索」的字段

设备数据集:每个点位+聚合方式组合成一个字段,查询参数固定(和趋势分析页面的参数类似)
字段扩展
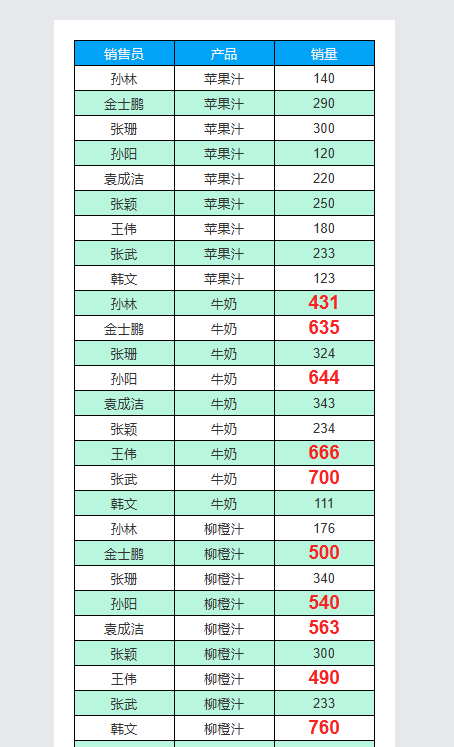
我们将左侧数据集中的字段「销售员」拖放到设计器中。在右侧面板中,可以看到它的类型变成了「数据集」。
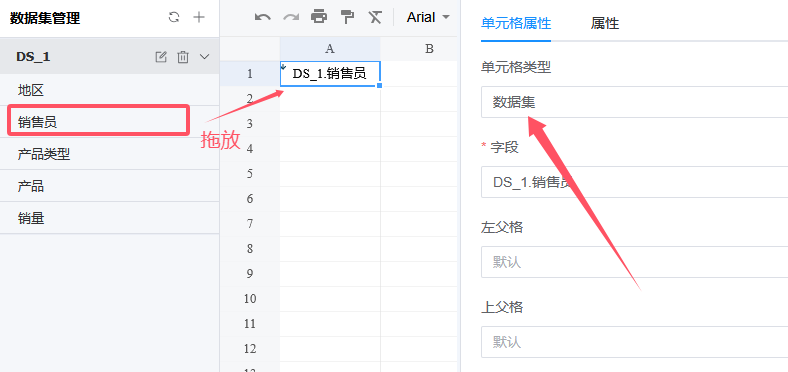
保存预览。可以看到,设计器中的提示文字「DS_1.销售员」并没有在展开后出现,取而代之的是数据集中实际存在的「销售员」字段的值,这些值纵向排成一列,从模板中的位置起始向下排布。

我们称这种行为叫数据集字段的扩展。
术语「扩展」:报表展开时,使用数据集中实际的字段值替换模板中字段单元格称为「扩展」
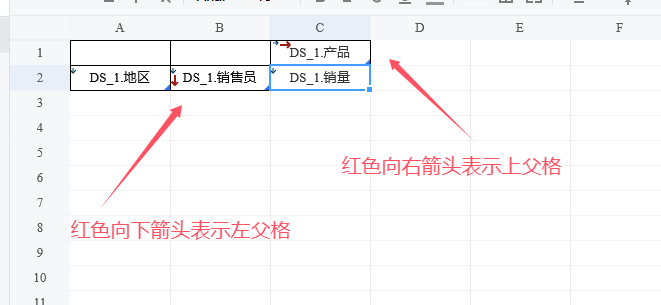
设计器中,单元格左上角有一个向下的蓝色箭头,这对应着右侧面板中的扩展方向:纵向扩展,效果就是刚才看到的,字段值纵向排布。
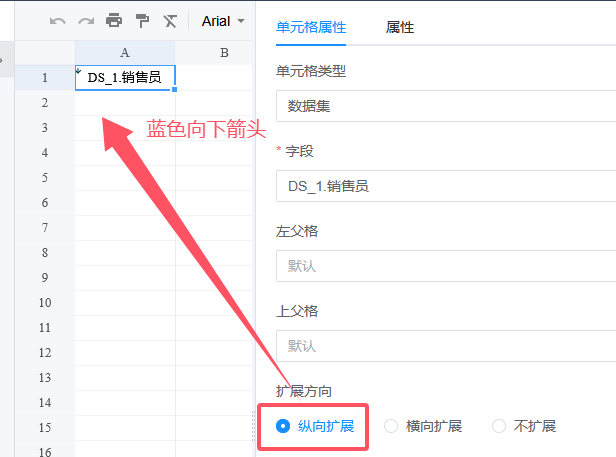
将扩展改为横向扩展,此时,设计器中的箭头变成了向右的箭头。
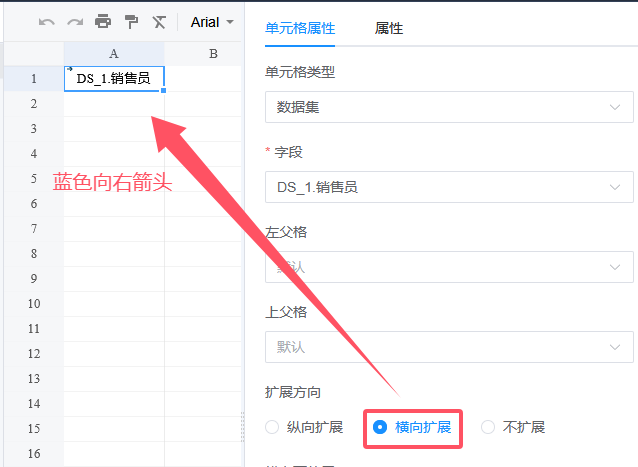
保存预览,可以看到在横向扩展时,字段值横向排成一行,从模板中的位置起始向右排布。

将扩展方向改为不扩展,单元格就会没有蓝色箭头。(未选中状态下,右下角会有一个蓝色三角形作为标识。)
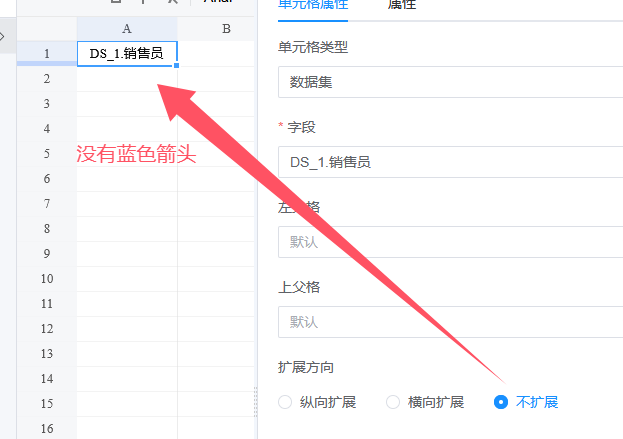
展开后,所有销售员都会挤到一个单元格中。
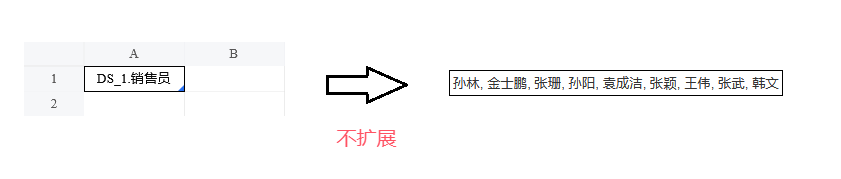
注意:这里的「不扩展」指的是扩展方向上,不向下方和右侧延申,但由于填入的是真实的销售员而不是提示文字「DS_1.销售员」,我们依然称这里进行了字段扩展操作。
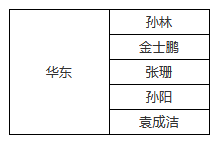
观察数据集的原始数据可以看到,「销售员」为「孙林」的数据有不止一条,其他销售员也是,而在报表展开后只有一个「孙林」。这是字段扩展时的默认行为,会对实际的字段值进行去重,并按照值在数据集中的出现顺序排列。我们在后面的章节会介绍如何取消默认的去重行为。
我们将数据集中的字段「地区」拖放到设计器中,保存预览,可以看到「DS_1.地区」字段扩展出了「华东」「华北」两个值。
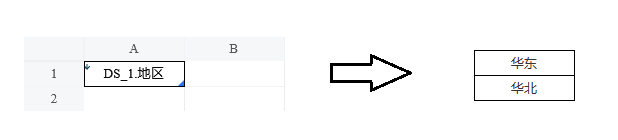
再将字段「DS_1.销售员」拖放到设计器中,让它紧贴「DS_1.地区」的右边。
保存预览:

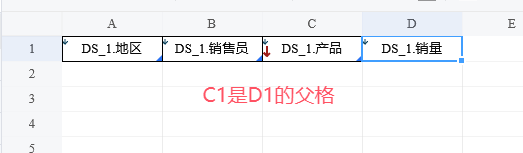
父子格用于表达像「地区」和「销售员」这两个字段的这种从属关系。
点击选中设计器中的「DS_1.销售员」单元格B1,可以看到「DS_1.地区」单元格A1的上方多了一个向下箭头。

这个箭头代表的含义是:「DS_1.地区」所处的单元格A1是当前选中的「DS_1.销售员」单元格B1的父格。
像这样两个纵向扩展的单元格相邻时,左边的单元格就会默认成为右边单元格的父格。
相对地,我们同时称右边的单元格时左边单元格的子格。
正是这种父子格关系使得报表展开后的实际数据也能在位置上满足字段的从属关系。
术语「父格」、「子格」:指报表模板中两个单元格之间的父子关系,用于表示它们要展开的数据存在从属关系。
父子格关系深入
父格关系有两个作用:
其一,在数据上,父格为子格提供数据过滤。
「华东」的列范围内→「孙林」等5人。
「华北」的列范围内→「张颖」等4人。
字段的扩展不仅是求得最终单元格内文本的过程,还是将数据集不断过滤、分组、传递给子格的过程。
其二,在布局上,子格的伸展会使父格被伸展。
模板中:「地区」与「销售员」单元格等高
展开后:「华东」与「孙林」等5个销售员加起来一起等高
这种对其关系,是在作为子格的「销售员」展开时完成的,每当子格多展开出一个销售员,对应的父格就被撑高一格,我们称父格这种被子格展开而撑大的行为为「伸展」。
术语「伸展」:父格因子格展开而被撑大的行为称为「伸展」
关闭父格的「纵向可伸展」或「横向可伸展」,可以禁止子格在对应方向上扩展时对父格的伸展。
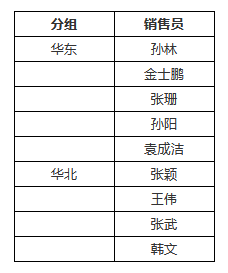
我们将「DS_1.销售员」向右移动一格,可以看到,父子格关系在中间夹有静态文本时依然有效。
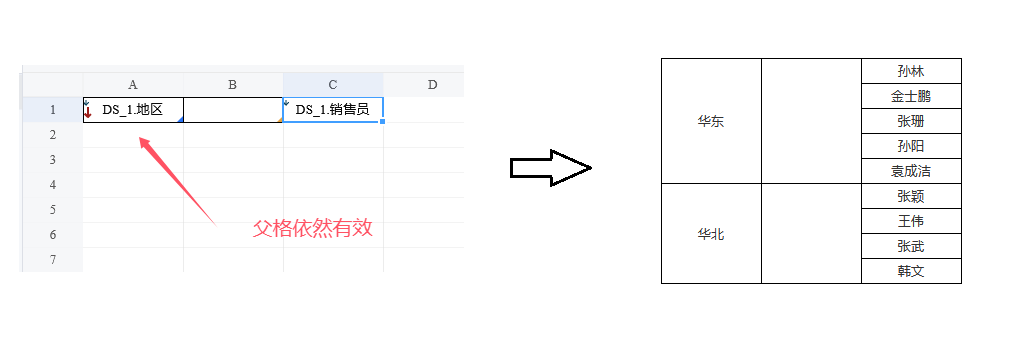
更准确地说,单元格是以从它的位置出发向左找到的第一个纵向扩展的单元格作为父格的。
如果一对父子格中,子格同时也是另外一个单元格的父格,由于父格会为子格提供数据过滤,那么子格会在父格过滤后的数据之上继续过滤提供给它的子格。
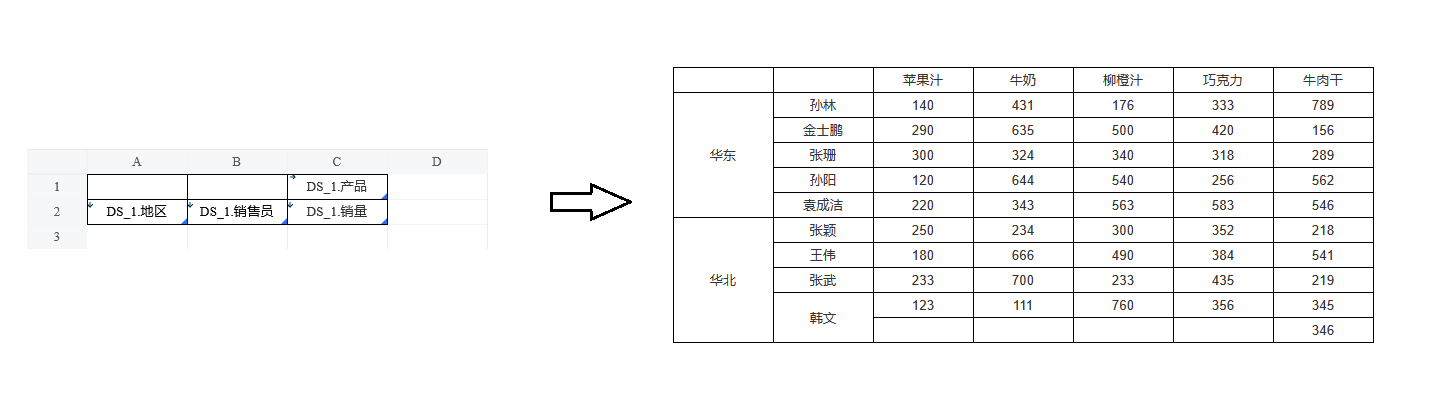
我们继续把字段「DS_1.产品」和「DS_1.销量」拖放到右侧。显然「DS_1.销售员」和「DS_1.产品」、「DS_1.产品」和「DS_1.销量」也满足上述父子格关系。
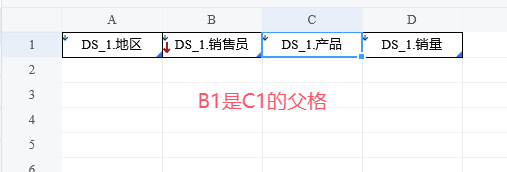
保存预览,可以看到「地区」给「销售员」提供的数据过滤,由「销售员」进一步过滤后提供给「产品」和「销量」;「销售员」作为父格被伸展时,「地区」也被继续伸展。

左父格和上父格
由于报表是向横、纵两个方向排布单元格的,所以字段扩展的方向也有横向、纵向。
进而,既然左右排布的单元格可以有父子格关系,那么上下排布的单元格也可以有父子格关系。
因此我们根据这个个不同,将父格区分为左父格和上父格。
术语「左父格」、「上父格」:模板中单元格的父格可细分为左父格和上父格两种,表示单元格在纵向、横向两个维度上为子格提供过滤
单元格最多只能有一个左父格和一个上父格。
上父格效果:

重点:将A1的扩展方向改为横向扩展。
左父格和上父格:综合使用
点击选中「DS_1.销量」:
保存预览:
根据我们上一节所说的,父子格关系不受静态文本的影响,而是向一个方向上查找得到的,这里将它具体到左父格和上父格,给出父格查找的规则:
默认父格规则:
单元格从其位置出发依次向左找到的第一个纵向扩展的单元格为其左父格。如果查找到最左边的单元格也没查找到,则没有左父格。
单元格从其位置出发依次向上找到的第一个横向扩展的单元格为其上父格。如果查找到最上边的单元格也没查找到,则没有上父格。
这里说的「依次向左」、「依次向上」,指的是如果遇到合并的单元格,则继续查找时从合并单元格的左上角继续向左、向上。
注意:默认父格规则只与位置和扩展方向有关,与单元格类型无关。
如果将默认父格的扩展方向改为「不扩展」,它就不再满足上述规则。

自定义父格
左父格和上父格的称法,单纯是因为默认父格规则中,一个是向左查找的,一个是向上查找的。
而事实上,左父格可以不在左侧,上父格也可以不在上方。
选中单元格后,我们可以修改右侧面板中的「左父格」和「上父格」为「无」或者「自定义」,来覆盖默认的父格规则。
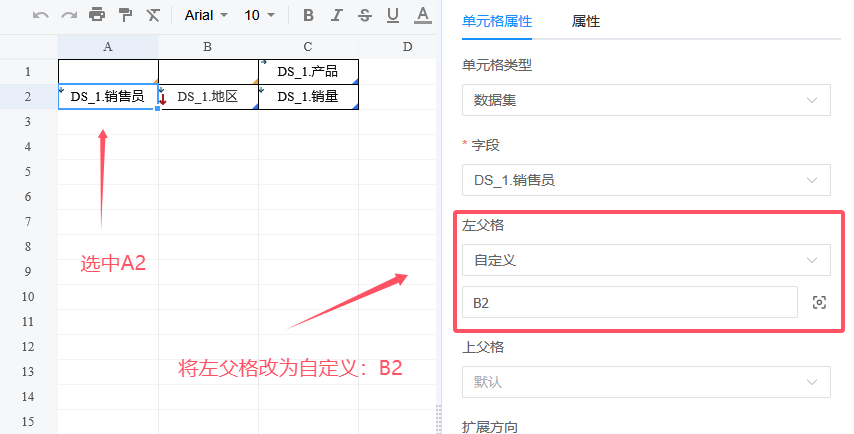
我们交换「DS_1.地区」和「DS_1.销售员」的位置。
在默认规则下,「DS_1.销售员」会是「DS_1.地区」父格,但我们想交换这个父子关系。
选中「DS_1.销售员」,在右侧面板中,将左父格改为自定义:B2。
这是点击保存是会失败的,因为我们将「DS_1.销售员」的父格设为「DS_1.地区」后,「DS_1.地区」的父格依然根据默认规则是「DS_1.销售员」,父子格关系中出现了循环。
父子格关系不能出现循环
我们继续选中「DS_1.地区」,将其左父格改为无。
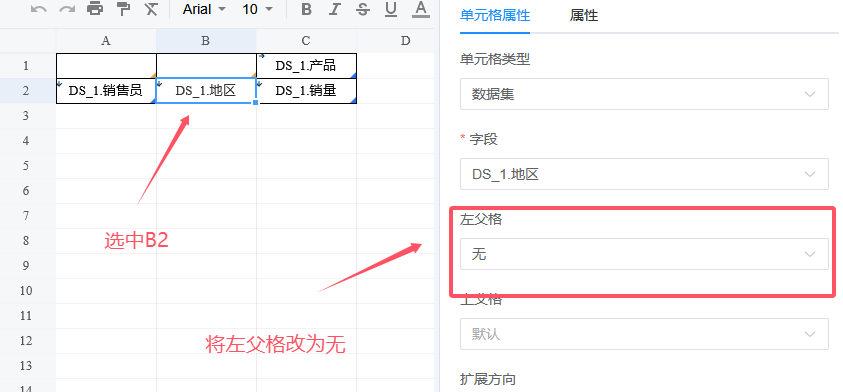
保存预览,成功调换了报表中地区和销售员的位置。
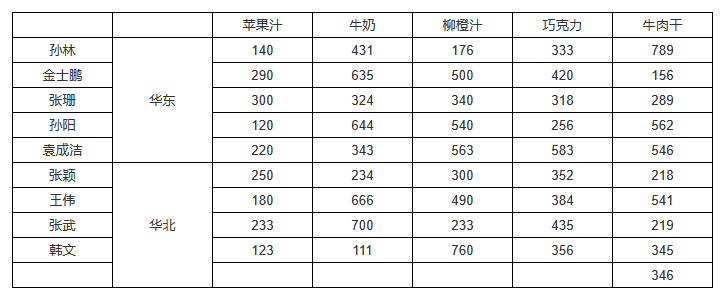
由于父子格关系带来的数据过滤效果具有传递性,一般来说,最左边和最上边的单元格会为右侧、下方所有单元格提供过滤。如果最左边和最上边的单元格也需要其他单元格提供数据过滤的话,那么它必然具有自定义的父格。而如果这个最左边、最上边的单元格不扩展的话,过滤效果就无法传递给子格。
所以这里我们在默认父格规则上进行一次补充:
默认父格规则(补充版):
单元格从其位置出发依次向左找到的第一个纵向扩展的单元格为其左父格。如果查找到最左边的单元格也没查找到,则当最左边单元格有自定义父格时,以这个自定义的父格为查找到的左父格,否则没有左父格。
单元格从其位置出发依次向上找到的第一个横向扩展的单元格为其上父格。如果查找到最上边的单元格也没查找到,则当最上边单元格有自定义父格时,以这个自定义的父格为查找到的上父格,否则没有上父格。
自定义父格:自由报表
在前面的例子中我们看到,当「DS_1.地区」扩展出「华东」、「华北」时,作为子格的「DS_1.销售员」会在「华东」、「华北」之下分别展开。那么,如果有一个静态文本单元格是地区的子格的话,这个静态文本也会在「华东」、「华北」之下分别存在一份。
我们为之前的例子添加标题,然后把两个标题单元格的父格改为「DS_1.地区」。
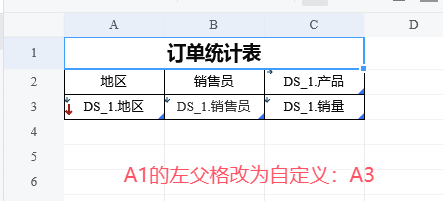
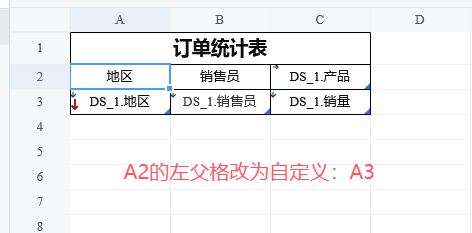
因为最左侧单元格A2设置了自定义父格A3,所以B2和C2的默认父格也是A3。
实现的「自由报表」效果:
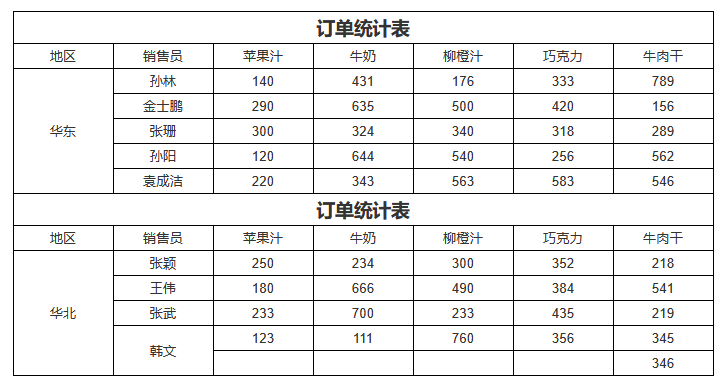
思考:如何为两张子表添加空行?
报表设计进阶
发布报表
当你的报表设计达到了一个可以提供给别人看的阶段的时候,点击发布按钮,这样就可以在列表页面查看到报表了
发布历史可以查看和回滚已经发布过的报表
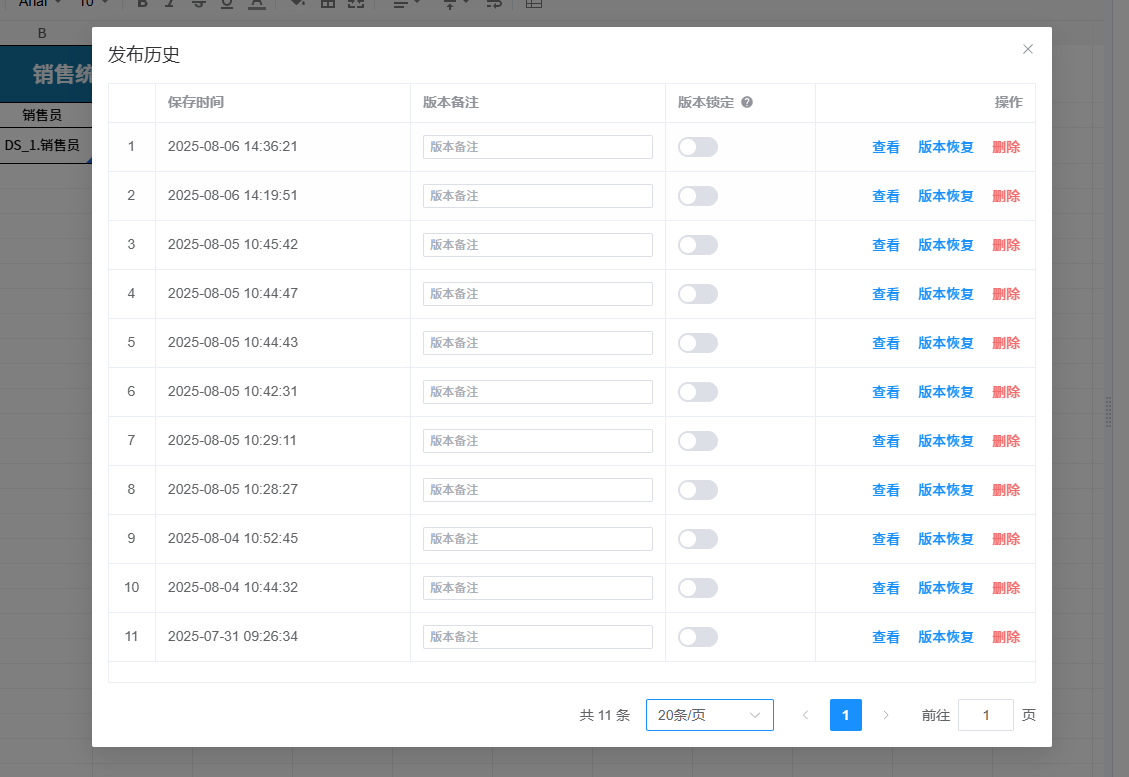
默认会自动记录最后20次发布,当次数达到上限时会自动删除前面的记录
将想要保存的记录的版本锁定打开后,该条记录就不会被滚动删除,需要注意的是允许锁定的数量为 (最大存储数 - 1),当达到最大锁定数量时将不允许新增锁定
点击版本恢复按钮会将当前报表的设计恢复到对应的版本
点击查看可以预览该历史记录版本的报表渲染
导入/导出报表设计
使用导出按钮来导出当前报表的设计
在另一个报表点击导入按钮选择刚才导出的配置
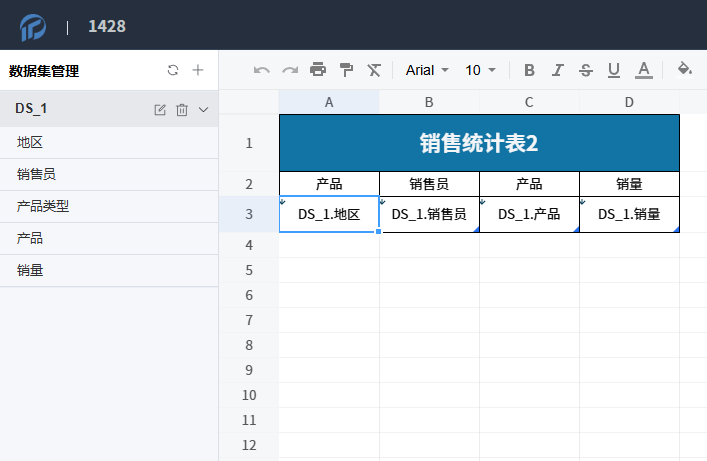
会发现另一个报表中配置的数据集与报表设计被导入了。
过滤条件
如果数据集中包含冗余数据,可以通过数据过滤表达式在分组之前对数据进行过滤。
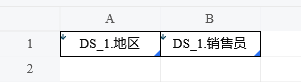
A1的过滤条件:data.地区 == "华东"
更好的方式是,直接在数据集上设置查询参数:
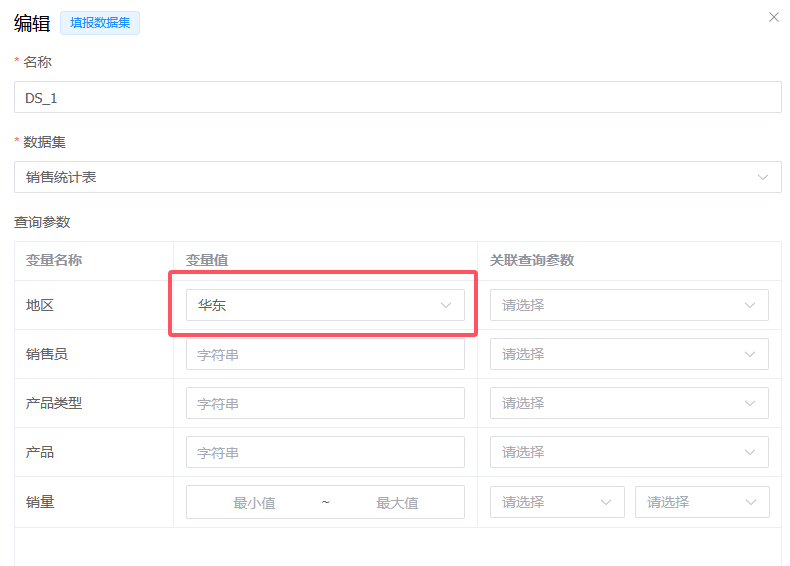
如果查询参数无法在报表设计时确定,可以添加为整个报表的参数:
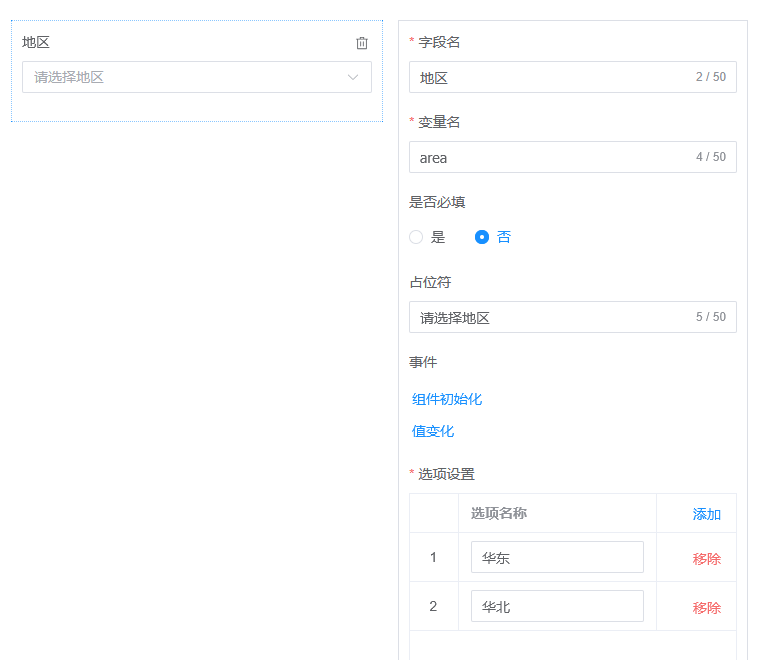
然后将数据集查询参数绑定到报表的查询参数:
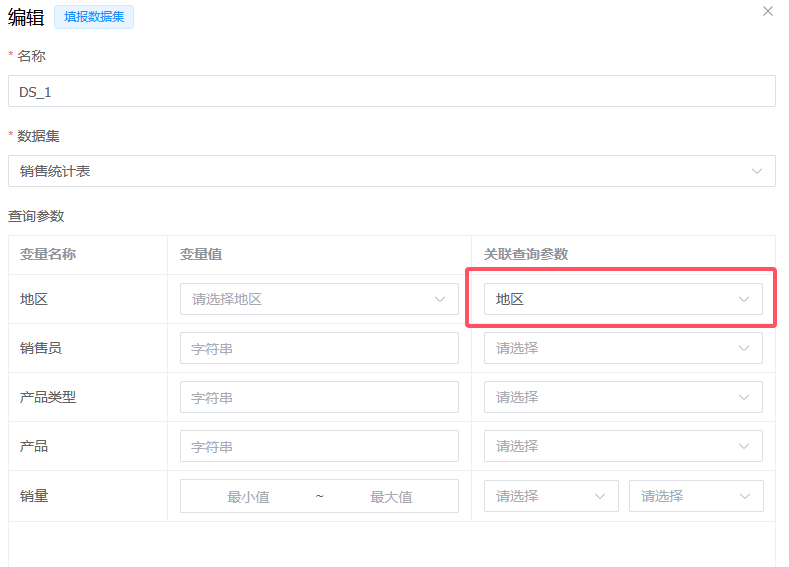
数据集不支持查询参数时,也可以在表达式中使用查询参数:
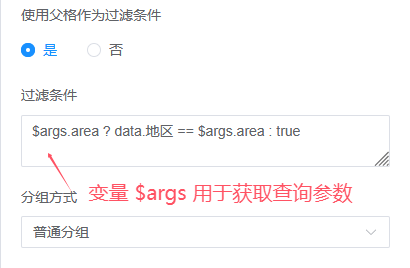
过滤条件:数据集关联
数据过滤另一个重要的用途是,实现多个数据集之间的数据关联呈现。

B2的过滤条件:DS_1.some('销售员', data.姓名)
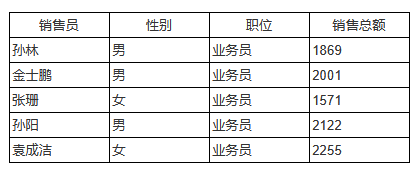
本例中销售员和销售总额来自数据集DS_1,而性别和职位来自另一个数据集。
父格作为过滤条件
关闭「父格作为过滤条件」的常见使用场景:自关联和重复关联

C2的过滤条件:DS_1.some('parentID', data.id)
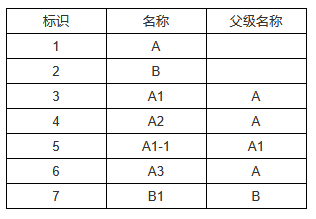

D2的过滤条件:DS_2.some('executor', data.雇员ID)
E2的过滤条件:DS_2.some('reviewer', data.雇员ID)
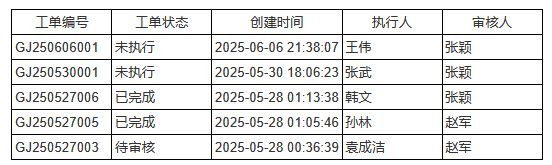
这里工单编号、工单状态、创建时间来自DS_2。
分组表达式
字段扩展时默认按指定字段值相同的分成一组。
使用分组表达式,可以将数据集中的每一条数据(作为表达式变量data)映射到一个值,按返回值相等的进行分组。我们将这个返回值称为分组值。
术语「分组值」:分组表达式将数据集中的每一条数据映射到的值,未设置分组表达式时以指定字段的值为分组值
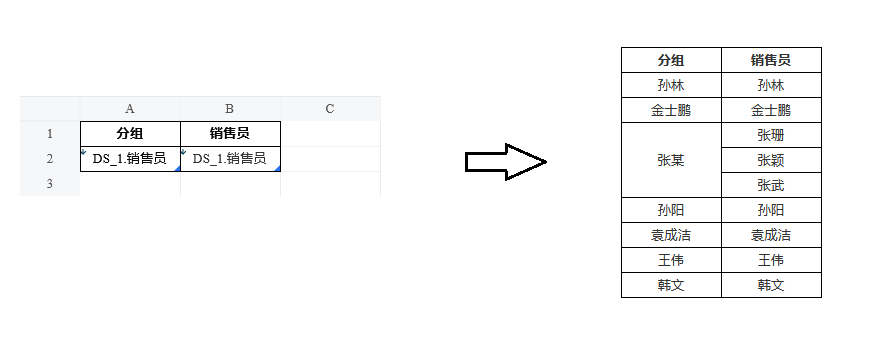
A2的分组表达式:data.销售员.startsWith("张") ? "张某" : data.销售员
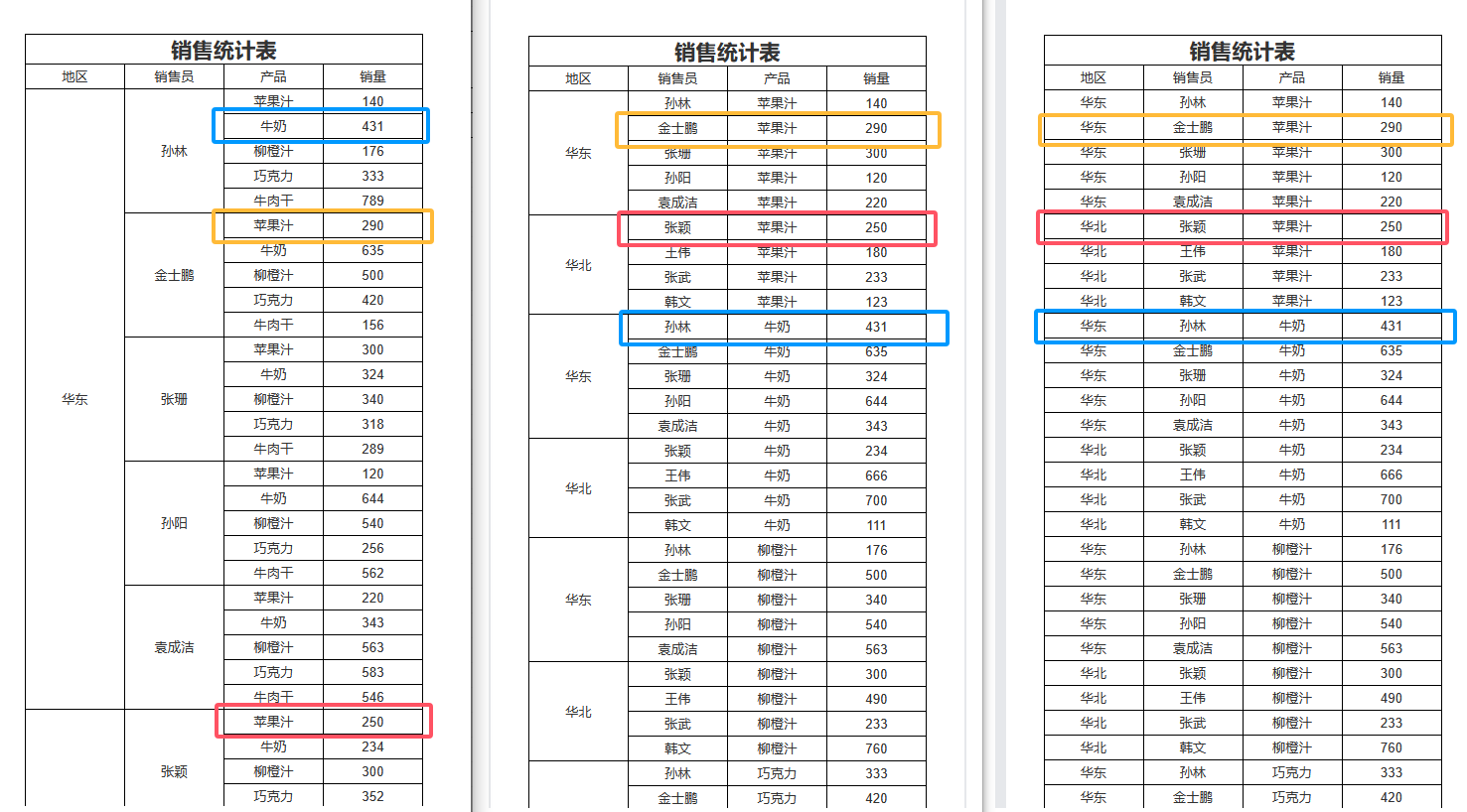
分组方式:普通分组、相邻连续分组、列表
(普通分组、相邻连续分组、列表)
普通分组(默认):将数据重新排序,分组值相同的归为一组。
相邻连续分组:保留原始顺序,如果相邻的两条数据分组值相同,归为一组。
列表:保留原始顺序,每条数据各自一组。
分组方式:汇总
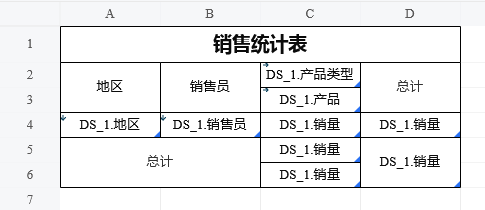
汇总统计最重要的一点是要正确设置父格,以确定被汇总的数据范围。
C4的扩展方向选择不扩展。
C5的上父格(默认)为C3,为地区+产品范围内的汇总。
C6的上父格设置为C2,为地区+产品类型范围内的汇总。
D4的左父格(默认)为B4,为地区+销售员范围内的汇总。
D5的左父格设置为A4,为地区范围内的汇总。
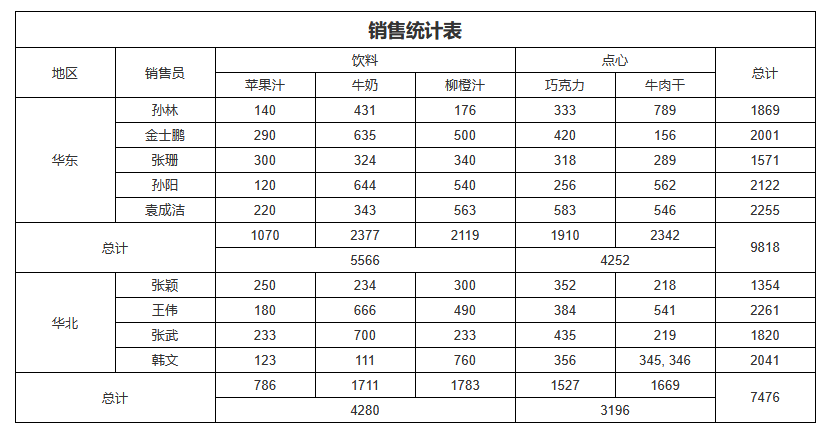
分组方式:自定义分组
普通分组、相邻连续分组都是比较分组值,按「相等」的规则划分为一组。
自定义分组,则可以用于替代「相等」规则,改为一组断言表达式,按表达式返回true的划分到对应的分组。
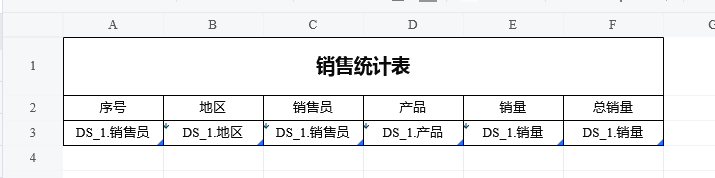
模板如下:

B2设为横向扩展。
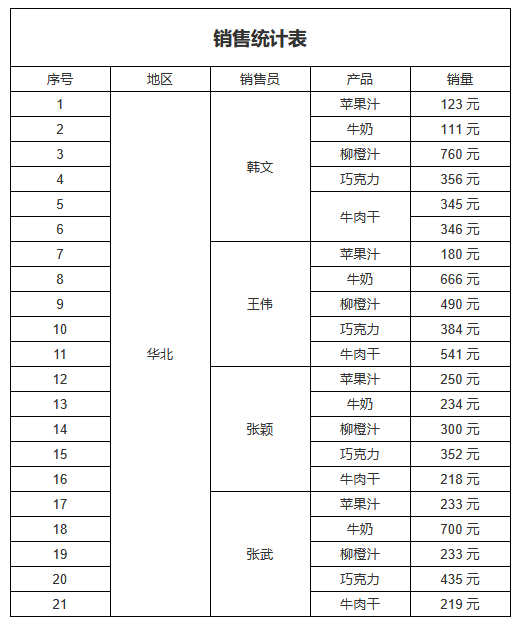
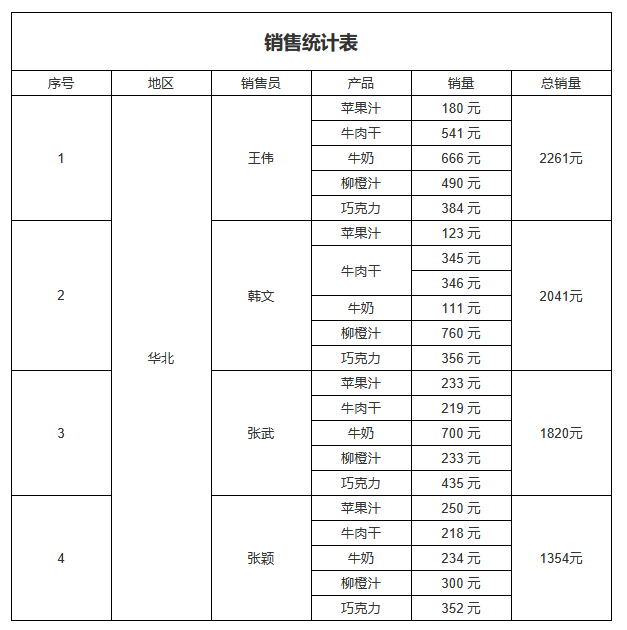
A2先设置分组表达式,从原始数据集DS_1计算以data对应销售员的销量之和作为分组值。
然后设置三个自定义分组,分别设置分组值大于3000、2000、1500的断言。

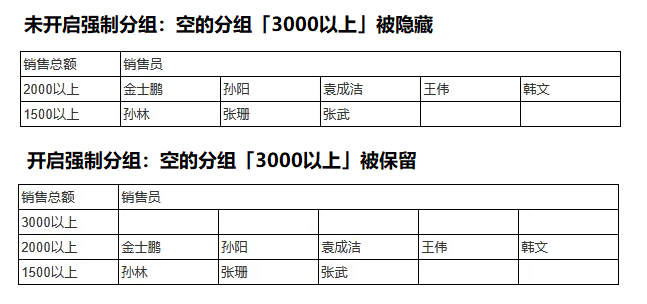
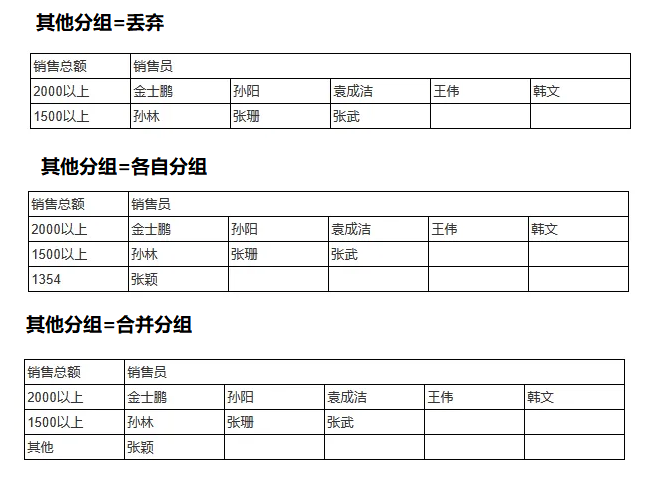
「强制分组」:如果一个分组没有匹配到任何数据,是否保留一个空的分组。
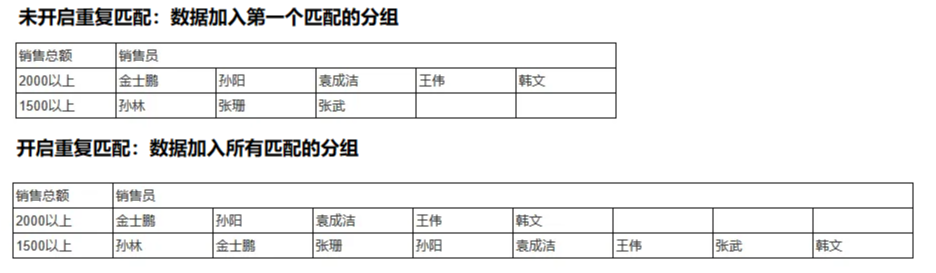
「重复分组」:如果关闭,数据划分到第一个匹配成功的分组,开启则划分到所有匹配成功的分组
「其他分组=丢弃」:如果所有分组都未匹配,丢弃数据
「其他分组=单独分组」:所有分组都未匹配的数据,继续按照「普通分组」模式进行分组,形成的分组将于预定义的分组并列。
「其他分组=合并」:所有分组都未匹配的数据,统一放在一个指定名称的分组内。
分组排序
原始顺序:
在地区范围内,按销量之和给销售员排序:
实现方法:
A3字段为销售员,父格C3,不扩展,格式化cellIndex + 1。
F3父格C3,汇总求和,不扩展。
C3分组排序表达式DS_1.sum("销量")。
在销售员范围内,按销量之和给产品排序:

A3字段为产品,父格D3,不扩展,格式化cellIndex + 1。
F3父格D3,汇总求和,不扩展。
D3分组排序表达式DS_1.sum("销量")。
条件样式
条件样式可以满足根据不同条件来控制单元格样式的需求
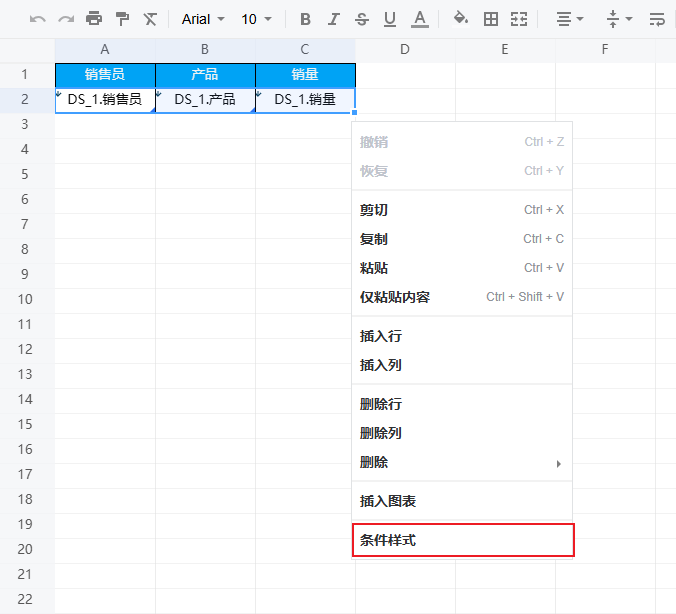
选中需要设置的单元格,鼠标右键后选择条件样式
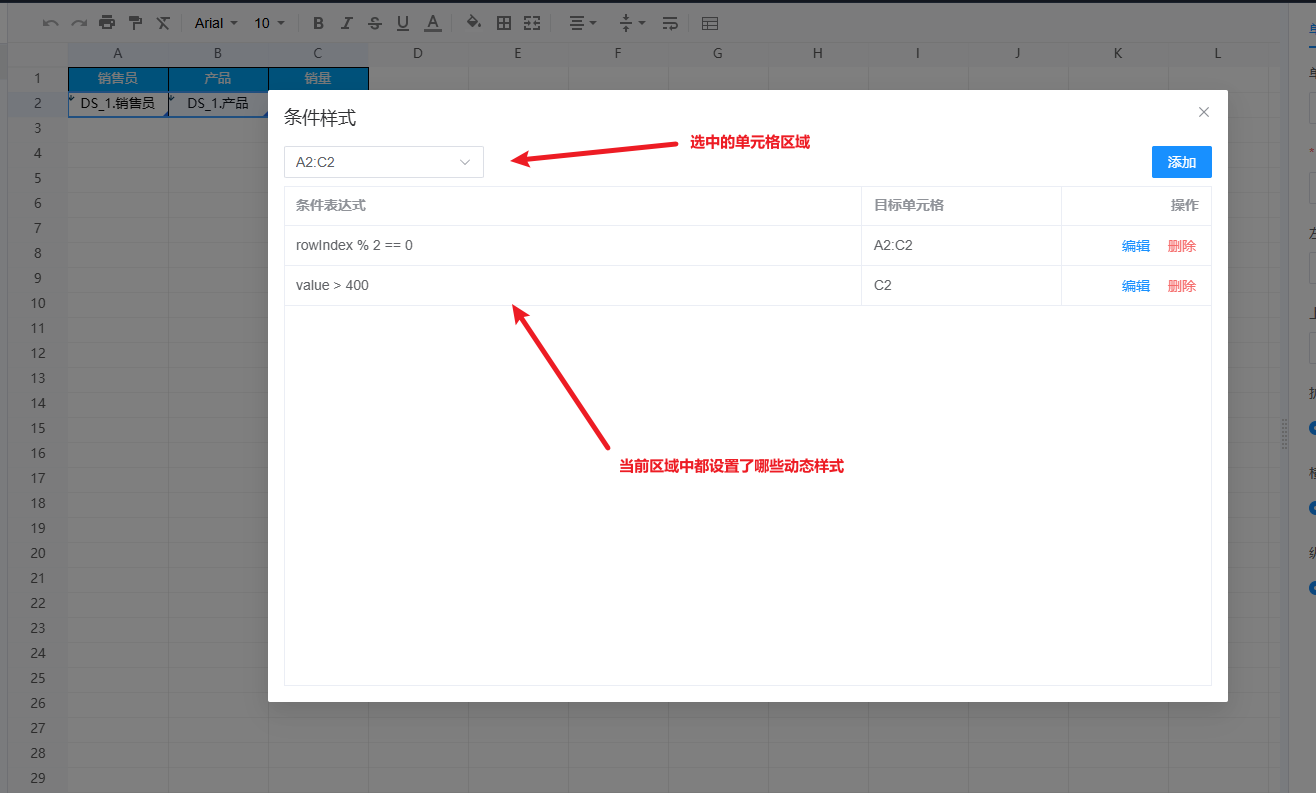
rowIndex: 当前行号 、value 当前单元格的值
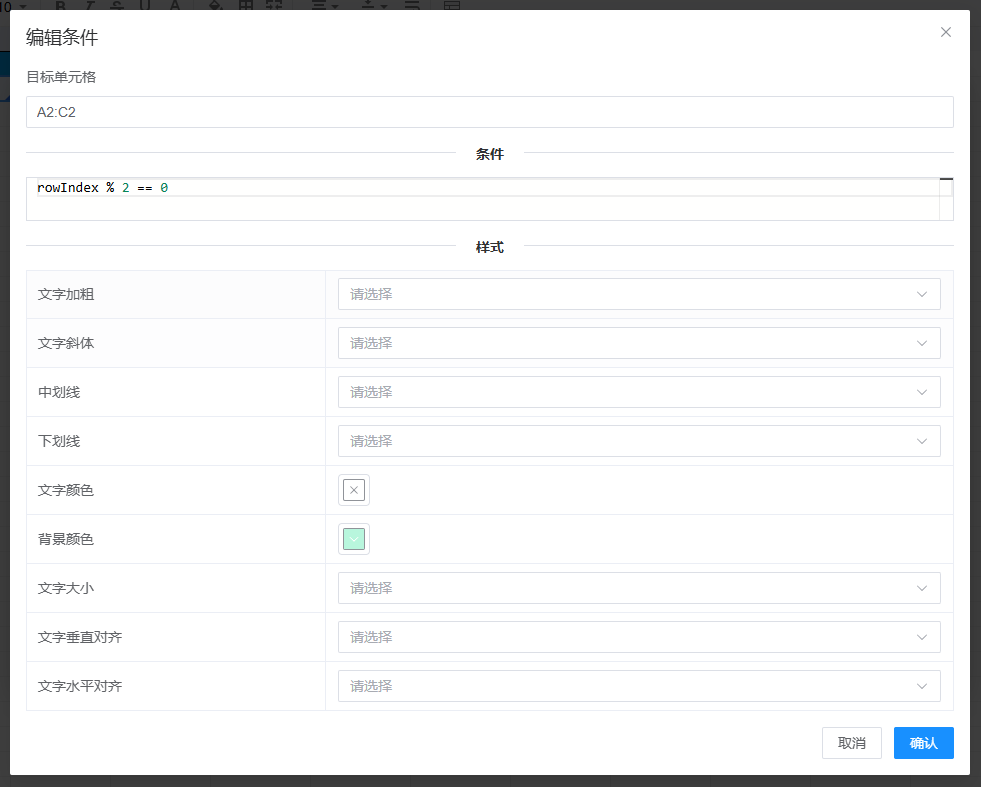
下面的案例为当为偶数行时设置特殊的背景色
格式化
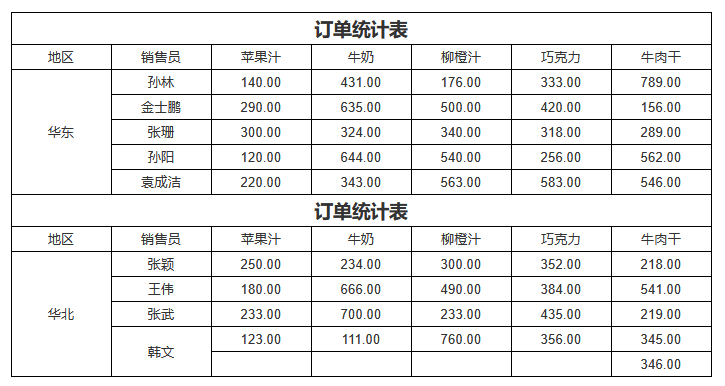
格式化:value.toFixed(2)
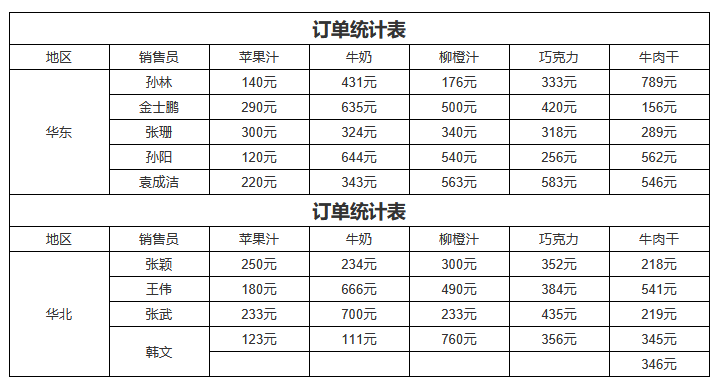
格式化:value + "元"
公式
汇总统计只能对单一字段进行汇总,使用公式可以实现更复杂的汇总。
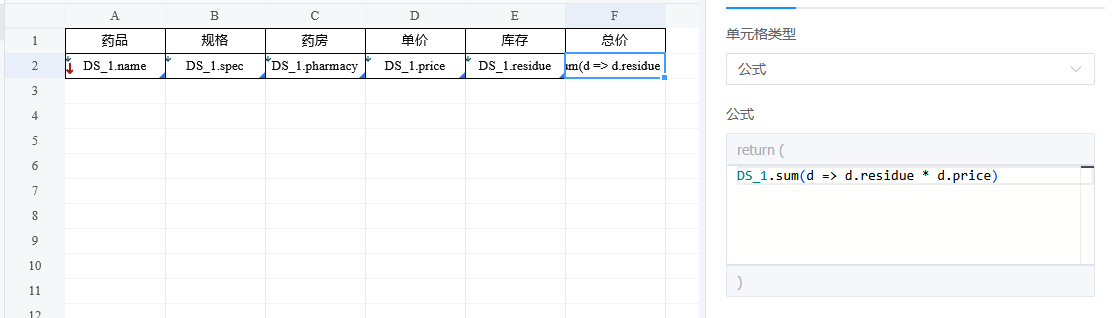
F2的公式:DS_1.sum(d => d.residue * d.price)
图表
在任意单元格中点击右键后选择插入图表
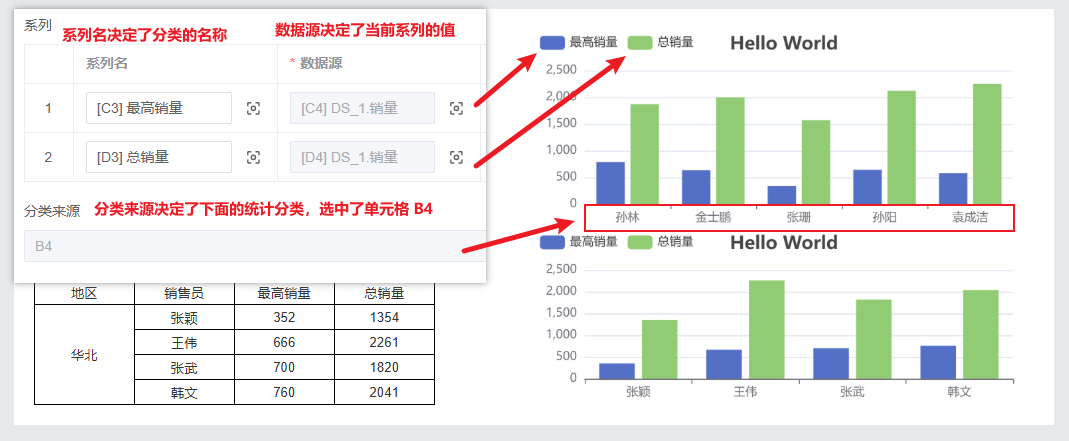
字段说明
图表类型: 决定要渲染的图表类型
系列: 系列决定了纵向坐标轴的值
分类来源: 决定了横向坐标轴的分类
图表标题: 决定了显示在图表上的文字
浮动: 默认的图表的宽高需要自行控制单元格合并来调整,开启浮动后图表的大小会自动撑开,不需要我们使用合并单元格来调整
图例位置: 决定是否要显示图例,还有图例的位置
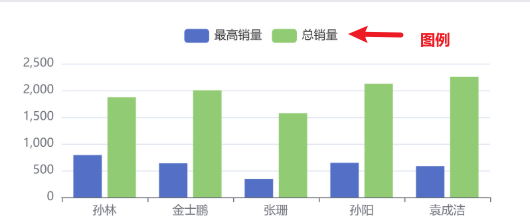
注意事项
将两个布局不同、甚至是数据都不相关的报表并排、并列展示。
有的时候是想让同一套数据用不同的布局展示,有时候是想让不相关的数据用相同的布局展示。
位于同一行、同一列的单元格,要么是有数据间的关联关系,要么是有布局上的关联关系。
像这种场景,应当拆分成多个报表,在同一张报表中展开之后很大概率是布局异常的。


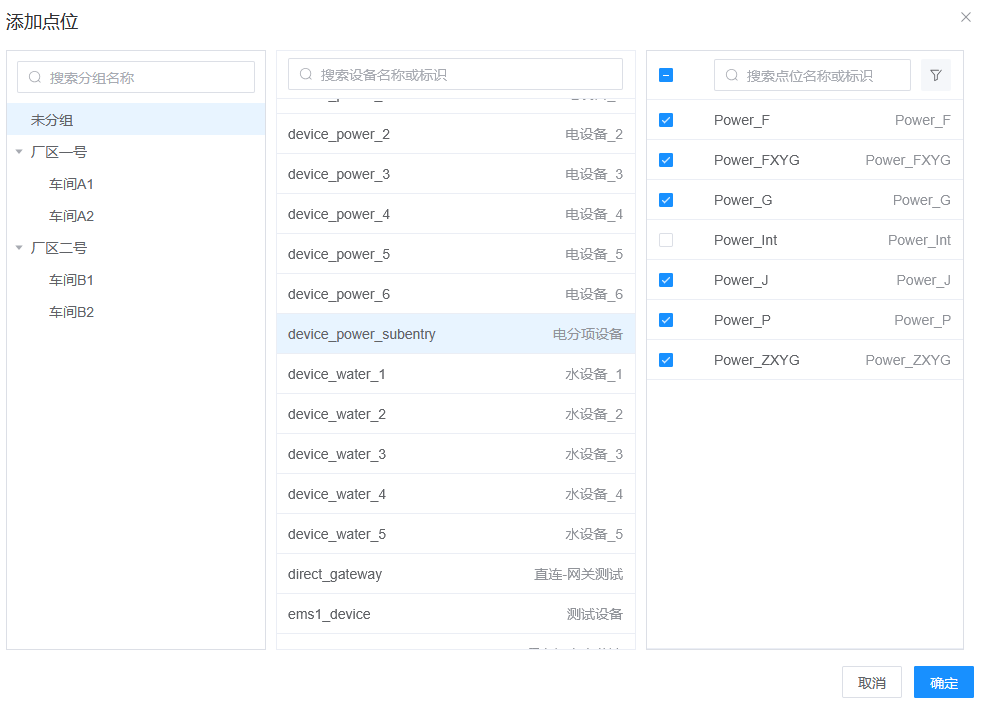
例1:设备报表
添加设备数据集,选择一组点位:
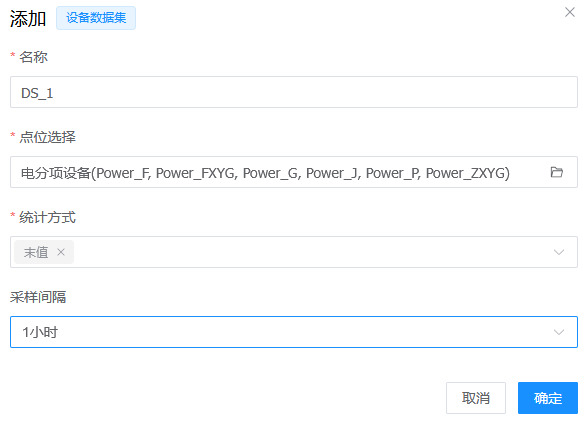
统计方式选择末值,采样间隔选择1小时:
依次将time和其他点位相关的字段拖放到编辑器中,并添加标题:

点击右上角的搜索配置
增加一个时间范围参数,并设为必填:
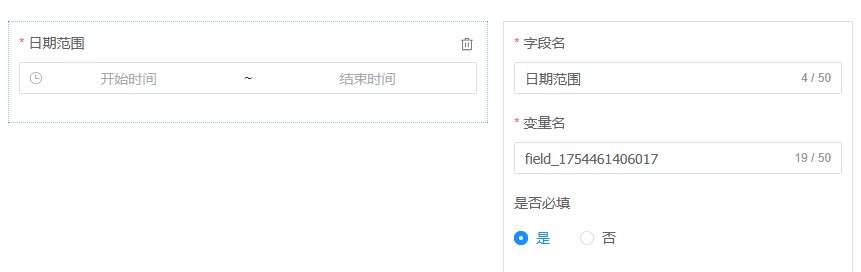
编辑数据集,将查询参数绑定到数据集上:
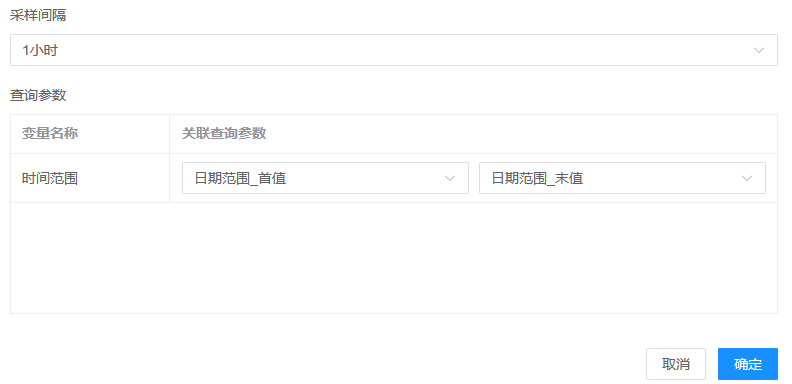
点击预览,在右侧面板中输入查询参数:
初步效果:
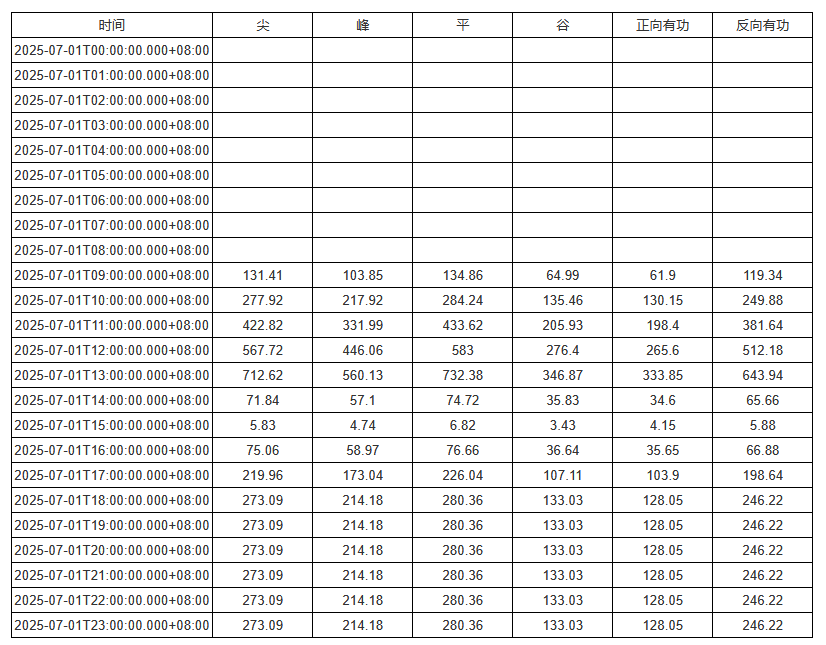
为时间添加格式化strftime(value, "%Y年%m月%d日 %H时"):
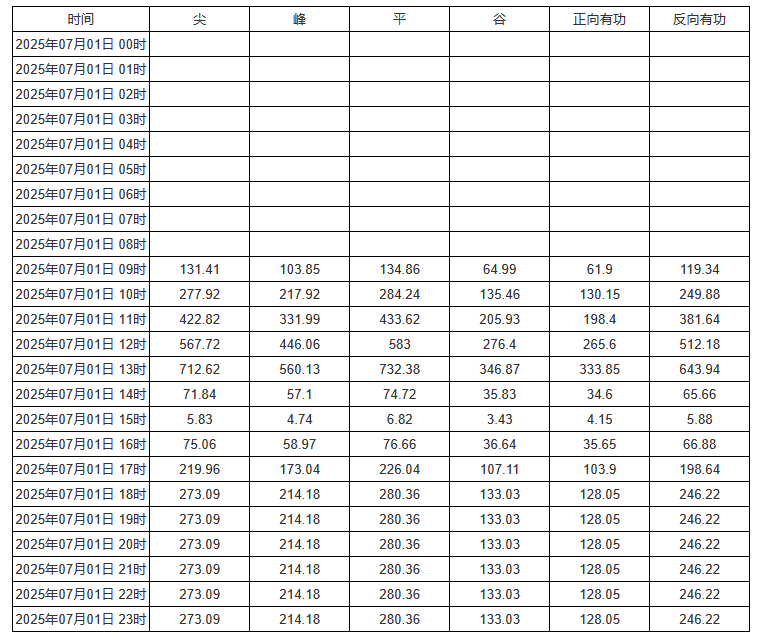
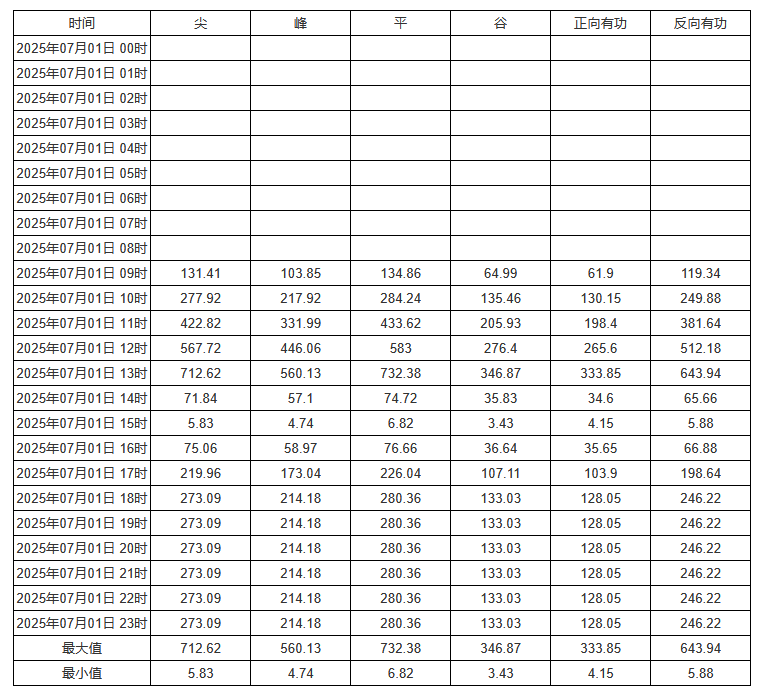
将点位字段各自复制一行,分组方式分别改为汇总最大值和最小值:

效果:
例2: 设置默认查询条件
在例1中,我们已经配置好了设备报表,但是每次查看时,我们都需要先手动选择一下需要查询的时间,很多时候我们可能都想要点击查看报表时默认查询今天的数据,在搜索配置中配置对应组件的组件初始化事件可以实现初始值。
点击右上角的搜索配置
选择需要设置初始值的组件,如日期范围组件,点击组件初始化
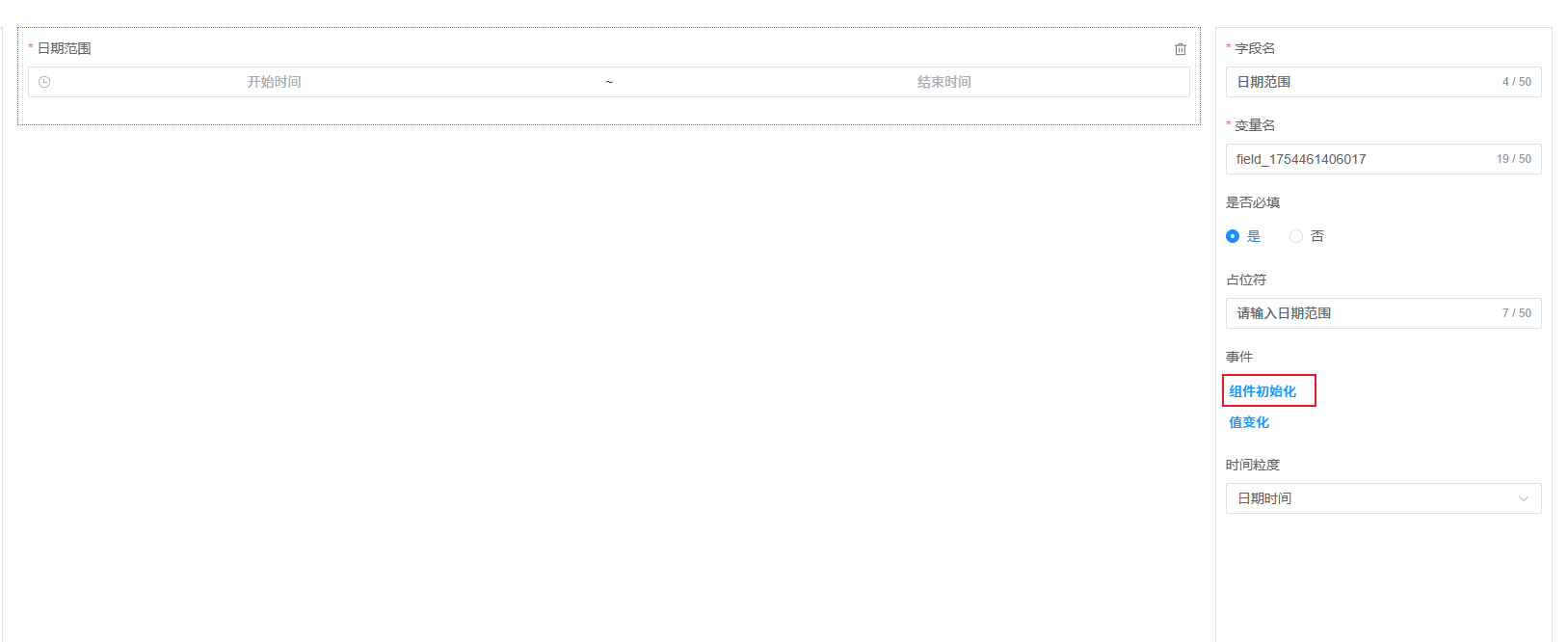
我们将默认查询时间设置为 当天的 00:00:00 ~ 当天的 23:59:59
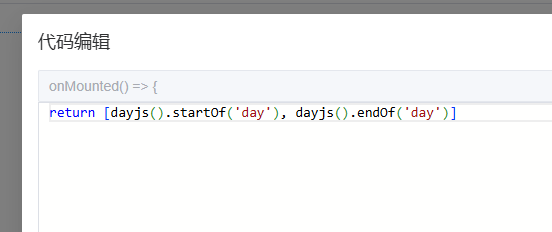
保存报表设计后点击预览按钮

会发现进入报表时不需要我们先手动选择日期范围了,搜索表单会自动填入今天的时间
同理,在不同的控件中返回不同的类型都可以实现默认值的效果
需要注意的是你的返回值要符合当前组件的数据格式,否则会产生错误